Text Analysis and Term Vectors
This section of the user guide presents an overview of the text analysis, text analytics and TF-IDF term vector functions in math expressions.
Text Analysis
The analyze function applies a Solr analyzer to a text field and returns the tokens emitted by the analyzer in an array.
Any analyzer chain that is attached to a field in Solr’s schema can be used with the analyze function.
In the example below, the text "hello world" is analyzed using the analyzer chain attached to the subject field in the schema.
The subject field is defined as the field type text_general and the text is analyzed using the analysis chain configured for the text_general field type.
analyze("hello world", subject)When this expression is sent to the /stream handler it responds with:
{
"result-set": {
"docs": [
{
"return-value": [
"hello",
"world"
]
},
{
"EOF": true,
"RESPONSE_TIME": 0
}
]
}
}Annotating Documents
The analyze function can be used inside of a select function to annotate documents with the tokens generated by the analysis.
The example below performs a search in "collection1".
Each tuple returned by the search function contains an id and subject.
For each tuple, the select function selects the id field and calls the analyze function on the subject field.
The analyzer chain specified by the subject_bigram field is configured to perform a bigram analysis.
The tokens generated by the analyze function are added to each tuple in a field called terms.
select(search(collection1, q="*:*", fl="id, subject", sort="id asc"),
id,
analyze(subject, subject_bigram) as terms)Notice in the output that an array of bigram terms have been added to the tuples:
{
"result-set": {
"docs": [
{
"terms": [
"text analysis",
"analysis example"
],
"id": "1"
},
{
"terms": [
"example number",
"number two"
],
"id": "2"
},
{
"EOF": true,
"RESPONSE_TIME": 4
}
]
}
}Text Analytics
The cartesianProduct function can be used in conjunction with the analyze function to perform a wide range of text analytics.
The cartesianProduct function explodes a multivalued field into a stream of tuples.
When the analyze function is used to create the multivalued field, the cartesianProduct function will explode the analyzed tokens into a stream of tuples.
This allows analytics to be performed over the stream of analyzed tokens and the result to be visualized with Zeppelin-Solr.
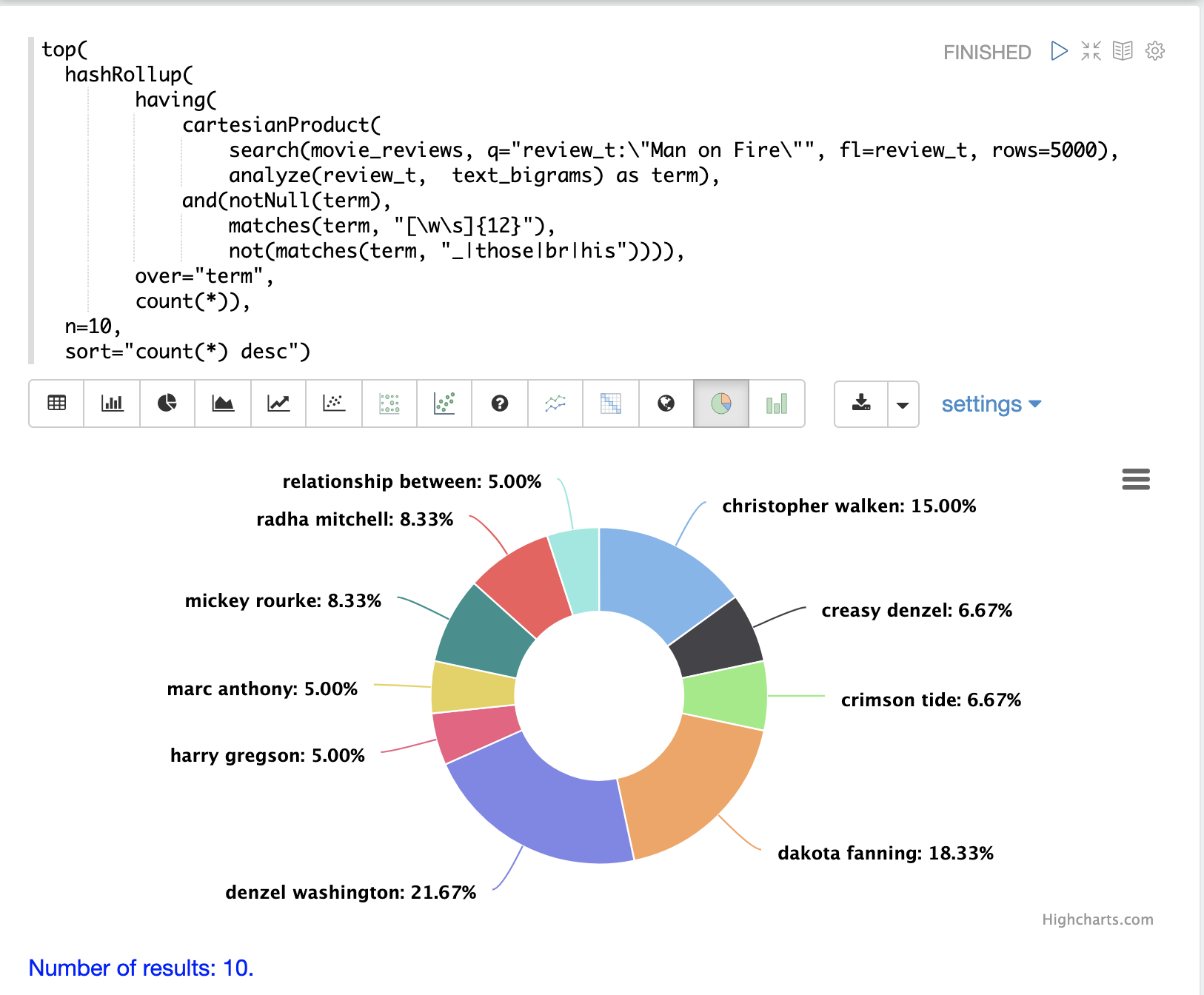
Example: Phrase Aggregation
An example performing phrase aggregation is used to illustrate the power of combining cartesianProduct and analyze.
In this example the search expression is performed over a collection of movie reviews.
The phrase query "Man on Fire" is searched for and the top 5000 results, by score are returned.
A single field from the results is return which is the review_t field that contains text of the movie review.
Then cartesianProduct function is run over the search results.
The cartesianProduct function applies the analyze function, which takes the review_t field and analyzes it with the analyzer attached to the text_bigrams schema field.
This analyzer emits the bigrams found in the text field.
The cartesianProduct function explodes each bigram into its own tuple with the bigram stored in the field term.
The stream of tuples, each containing a bigram, is then filtered by the having function
using regular expressions to select bigrams with a length of 12 or greater and to filter out bigrams that contain specific characters.
The hashRollup function then aggregates the bigrams and the top function emits the top 10 bigrams by count.
Then Zeppelin-Solr is used to visualize the top 10 ten bigrams.
Analyzers can be configured in many different ways to support aggregations over NLP entities (people, places, companies, etc.) as well as tokens extracted with regular expressions or dictionaries.
TF-IDF Term Vectors
The termVectors function can be used to build TF-IDF term vectors from the terms generated by the analyze function.
The termVectors function operates over a list of tuples that contain a field called id and a field called terms.
Notice that this is the exact output structure of the document annotation example above.
The termVectors function builds a matrix from the list of tuples.
There is row in the matrix for each tuple in the list.
There is a column in the matrix for each term in the terms field.
let(echo="c, d", (1)
a=select(search(collection3, q="*:*", fl="id, subject", sort="id asc"), (2)
id,
analyze(subject, subject_bigram) as terms),
b=termVectors(a, minTermLength=4, minDocFreq=0, maxDocFreq=1), (3)
c=getRowLabels(b), (4)
d=getColumnLabels(b))The example below builds on the document annotation example.
| 1 | The echo parameter will echo variables c and d, so the output includes
the row and column labels, which will be defined later in the expression. |
| 2 | The list of tuples are stored in variable a.
The termVectors function operates over variable a and builds a matrix with 2 rows and 4 columns. |
| 3 | The termVectors function sets the row and column labels of the term vectors matrix as variable b.
The row labels are the document ids and the column labels are the terms. |
| 4 | The getRowLabels and getColumnLabels functions return the row and column labels which are then stored in variables c and d. |
When this expression is sent to the /stream handler it responds with:
{
"result-set": {
"docs": [
{
"c": [
"1",
"2"
],
"d": [
"analysis example",
"example number",
"number two",
"text analysis"
]
},
{
"EOF": true,
"RESPONSE_TIME": 5
}
]
}
}TF-IDF Values
The values within the term vectors matrix are the TF-IDF values for each term in each document. The example below shows the values of the matrix.
let(a=select(search(collection3, q="*:*", fl="id, subject", sort="id asc"),
id,
analyze(subject, subject_bigram) as terms),
b=termVectors(a, minTermLength=4, minDocFreq=0, maxDocFreq=1))When this expression is sent to the /stream handler it responds with:
{
"result-set": {
"docs": [
{
"b": [
[
1.4054651081081644,
0,
0,
1.4054651081081644
],
[
0,
1.4054651081081644,
1.4054651081081644,
0
]
]
},
{
"EOF": true,
"RESPONSE_TIME": 5
}
]
}
}Limiting the Noise
One of the key challenges when working with term vectors is that text often has a significant amount of noise which can obscure the important terms in the data.
The termVectors function has several parameters designed to filter out the less meaningful terms.
This is also important because eliminating the noisy terms helps keep the term vector matrix small enough to fit comfortably in memory.
There are four parameters designed to filter noisy terms from the term vector matrix:
minTermLength-
Optional
Default:
3The minimum term length required to include the term in the matrix.
minDocFreq-
Optional
Default:
.05The minimum percentage, expressed as a number between
0and1, of documents the term must appear in to be included in the index. maxDocFreq-
Optional
Default:
.5The maximum percentage, expressed as a number between
0and1, of documents the term can appear in to be included in the index. exclude-
Optional
Default: none
A comma-delimited list of strings used to exclude terms. If a term contains any of the excluded strings that term will be excluded from the term vector.