Documents Screen
The Documents screen provides a simple form allowing you to execute various Solr indexing commands in a variety of formats directly from the browser.
The screen allows you to:
-
Submit JSON, CSV or XML documents in Solr-specific format for indexing
-
Upload documents (in JSON, CSV or XML) for indexing
-
Construct documents by selecting fields and field values
|
There are other ways to load data, see also these sections: |
Common Fields
-
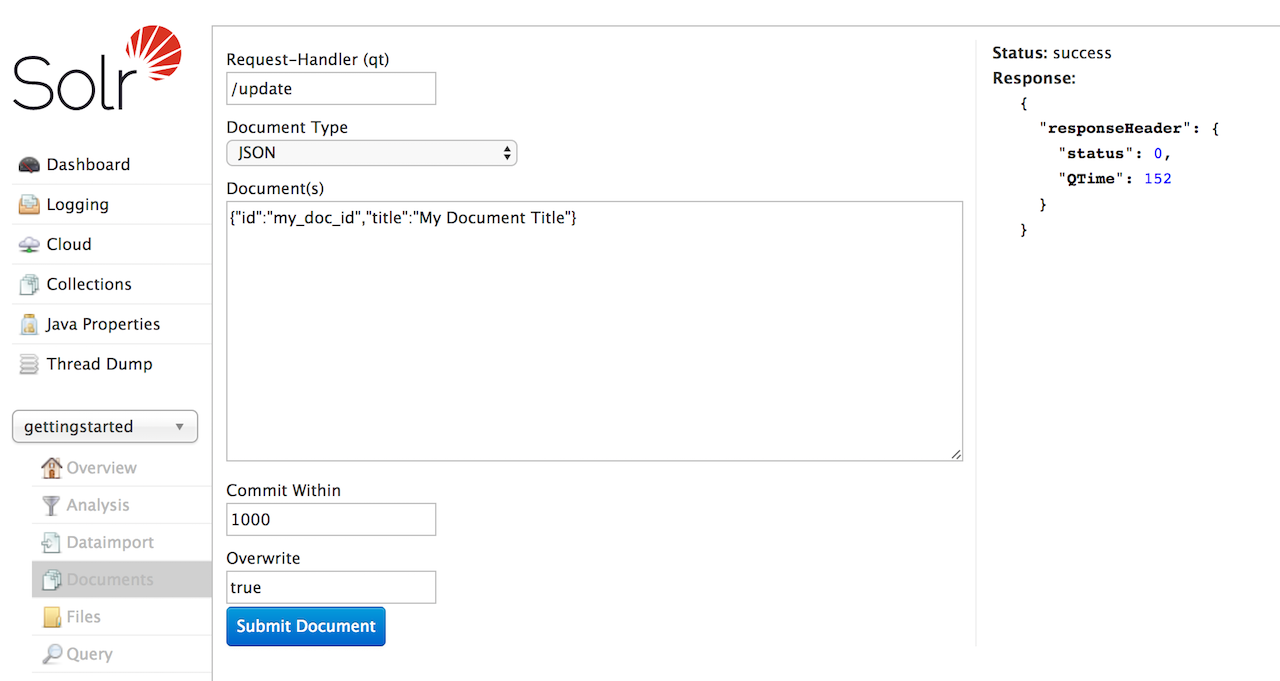
Request-Handler: The first step is to define the RequestHandler. By default
/updatewill be defined. Change the request handler to/update/extractto use Solr Cell. -
Document Type: Select the Document Type to define the format of document to load. The remaining parameters may change depending on the document type selected.
-
Document(s): Enter a properly-formatted Solr document corresponding to the
Document Typeselected. XML and JSON documents must be formatted in a Solr-specific format, a small illustrative document will be shown. CSV files should have headers corresponding to fields defined in the schema. More details can be found in Indexing with Update Handlers. -
Commit Within: Specify the number of milliseconds between the time the document is submitted and when it is available for searching.
-
Overwrite: If
truethe new document will replace an existing document with the same value in theidfield. Iffalsemultiple documents with the same id can be added.
|
Setting |
CSV, JSON and XML Documents
When using these document types the functionality is similar to submitting documents via curl or similar.
The document structure must be in a Solr-specific format appropriate for the document type.
Examples are illustrated in the Document(s) text box when you select the various types.
These options will only add or overwrite documents; for other update tasks, see the Solr Command option.
Document Builder
The Document Builder provides a wizard-like interface to enter fields of a document.
File Upload
The File Upload option allows choosing a prepared file and uploading it.
If using /update for the Request-Handler option, you will be limited to XML, CSV, and JSON.
Other document types (e.g., Word, PDF, etc.) can be indexed using the ExtractingRequestHandler (aka, Solr Cell).
You must modify the RequestHandler to /update/extract, which must be defined in your solrconfig.xml file with your desired defaults.
You should also add &literal.id shown in the "Extracting Request Handler Params" field so the file chosen is given a unique id.
More information can be found in Indexing with Solr Cell and Apache Tika.