Index Segments and Merging
Lucene indexes are stored in segments and Solr offers several parameters to control how new segments are written and when segments are merged.
Lucene indexes are "write-once" files: once a segment has been written to permanent storage (to disk), it is never altered. This means that indexes are actually comprised of several files which are each subsets of the full index. In order to prevent eternal fragmentation of the index, segments are periodically merged.
<indexConfig> in solrconfig.xml
The <indexConfig> section of solrconfig.xml defines low-level behavior of the Lucene index writers.
By default, the settings are commented out in the sample solrconfig.xml included with Solr, which means the defaults are used.
In most cases, the defaults are fine.
<indexConfig>
...
</indexConfig>Writing New Segments
The following elements can be defined under the <indexConfig> element and define when new segments are written ("flushed") to disk.
ramBufferSizeMB
Once accumulated document updates exceed this much memory space (defined in megabytes), then the pending updates are flushed.
This can also create new segments or trigger a merge.
Using this setting is generally preferable to maxBufferedDocs.
If both maxBufferedDocs and ramBufferSizeMB are set in solrconfig.xml, then a flush will occur when either limit is reached.
The default is 100 MB.
<ramBufferSizeMB>100</ramBufferSizeMB>maxBufferedDocs
Sets the number of document updates to buffer in memory before they are flushed as a new segment.
This may also trigger a merge.
The default Solr configuration sets to flush by RAM usage (ramBufferSizeMB).
<maxBufferedDocs>1000</maxBufferedDocs>useCompoundFile
Controls whether newly written (and not yet merged) index segments should use the Compound File Segments format.
The default is false.
<useCompoundFile>false</useCompoundFile>ramPerThreadHardLimitMB
Sets the maximum memory (defined in megabytes) consumption per thread triggering a forced flush if exceeded.
The given value must be greater than 0 and less than 2048 MB (2GB).
<ramPerThreadHardLimitMB>1945</ramPerThreadHardLimitMB>
This is an expert level parameter as it triggers forced flush even if ramBufferSizeMB has not been exceeded.
|
Merging Index Segments
The following settings define when segments are merged.
mergePolicyFactory
Defines how merging segments is done.
The default in Solr is to use TieredMergePolicy, which merges segments of approximately equal size, subject to an allowed number of segments per tier.
Other policies available are the LogByteSizeMergePolicy and LogDocMergePolicy.
For more information on these policies, please see the MergePolicy javadocs.
<mergePolicyFactory class="org.apache.solr.index.TieredMergePolicyFactory">
<int name="maxMergeAtOnce">10</int>
<int name="segmentsPerTier">10</int>
<double name="forceMergeDeletesPctAllowed">10.0</double>
<double name="deletesPctAllowed">33.0</double>
</mergePolicyFactory>Controlling Segment Sizes
The most common adjustment users make to the configuration of TieredMergePolicy (or LogByteSizeMergePolicy) are the "merge factors" to change how many segments should be merged at one time and, in the TieredMergePolicy case, the maximum size of an merged segment.
For TieredMergePolicy, this is controlled by setting the maxMergeAtOnce (default 10), segmentsPerTier (default 10) and maxMergedSegmentMB (default 5000) options.
LogByteSizeMergePolicy has a single mergeFactor option (default 10).
To understand why these options are important, consider what happens when an update is made to an index using LogByteSizeMergePolicy: Documents are always added to the most recently opened segment.
When a segment fills up, a new segment is created and subsequent updates are placed there.
If creating a new segment would cause the number of lowest-level segments to exceed the mergeFactor value, then all those segments are merged together to form a single large segment.
Thus, if the merge factor is 10, each merge results in the creation of a single segment that is roughly ten times larger than each of its ten constituents.
When there are 10 of these larger segments, then they in turn are merged into an even larger single segment.
This process can continue indefinitely.
When using TieredMergePolicy, the process is the same, but instead of a single mergeFactor value, the segmentsPerTier setting is used as the threshold to decide if a merge should happen, and the maxMergeAtOnce setting determines how many segments should be included in the merge.
Choosing the best merge factors is generally a trade-off of indexing speed vs. searching speed. Having fewer segments in the index generally accelerates searches, because there are fewer places to look. It also can also result in fewer physical files on disk. But to keep the number of segments low, merges will occur more often, which can add load to the system and slow down updates to the index.
Conversely, keeping more segments can accelerate indexing, because merges happen less often, making an update is less likely to trigger a merge. But searches become more computationally expensive and will likely be slower, because search terms must be looked up in more index segments. Faster index updates also means shorter commit turnaround times, which means more timely search results.
Controlling Deleted Document Percentages
When a document is deleted or updated, the document is marked as deleted but it not removed from the index until the segment is merged.
There are two parameters that can can be adjusted when using the default TieredMergePolicy that influence the number of deleted documents in an index.
forceMergeDeletesPctAllowed-
Optional
Default:
10.0When the external
expungeDeletescommand is issued, any segment that has more than this percent deleted documents will be merged into a new segment and the data associated with the deleted documents will be purged. A value of0.0will make expungeDeletes behave essentially identically tooptimize. deletesPctAllowed-
Optional
Default:
33.0During normal segment merging, a best effort is made to insure that the total percentage of deleted documents in the index is below this threshold. Valid settings are between 20% and 50%. 33% was chosen as the default because as this setting approaches 20%, considerable load is added to the system.
Customizing Merge Policies
If the configuration options for the built-in merge policies do not fully suit your use case, you can customize them either by creating a custom merge policy factory that you specify in your configuration, or by configuring a merge policy wrapper which uses a wrapped.prefix configuration option to control how the factory it wraps will be configured:
<mergePolicyFactory class="org.apache.solr.index.SortingMergePolicyFactory">
<str name="sort">timestamp desc</str>
<str name="wrapped.prefix">inner</str>
<str name="inner.class">org.apache.solr.index.TieredMergePolicyFactory</str>
<int name="inner.maxMergeAtOnce">10</int>
<int name="inner.segmentsPerTier">10</int>
</mergePolicyFactory>The example above shows Solr’s SortingMergePolicyFactory being configured to sort documents in merged segments by "timestamp desc", and wrapped around a TieredMergePolicyFactory configured to use the values maxMergeAtOnce=10 and segmentsPerTier=10 via the inner prefix defined by SortingMergePolicyFactory 's wrapped.prefix option.
For more information on using SortingMergePolicyFactory, see the segmentTerminateEarly parameter.
mergeScheduler
The merge scheduler controls how merges are performed.
The default ConcurrentMergeScheduler performs merges in the background using separate threads.
The alternative, SerialMergeScheduler, does not perform merges with separate threads.
The ConcurrentMergeScheduler has the following configurable attributes.
The defaults for these attributes are dynamically set based on whether the underlying disk drive is rotational disk or not.
Refer to Dynamic Defaults for ConcurrentMergeScheduler for more details.
maxMergeCount-
Optional
Default: none
The maximum number of simultaneous merges that are allowed. If a merge is necessary yet we already have this many threads running, the indexing thread will block until a merge thread has completed. Note that Solr will only run the smallest
maxThreadCountmerges at a time. maxThreadCount-
Optional
Default: none
The maximum number of simultaneous merge threads that should be running at once. This must be less than
maxMergeCount. ioThrottle-
Optional
Default: none
A Boolean value (
trueorfalse) to explicitly control I/O throttling. By default throttling is enabled and the CMS will limit I/O throughput when merging to leave other (search, indexing) some room.
<mergeScheduler class="org.apache.lucene.index.ConcurrentMergeScheduler"/><mergeScheduler class="org.apache.lucene.index.ConcurrentMergeScheduler">
<int name="maxMergeCount">9</int>
<int name="maxThreadCount">4</int>
</mergeScheduler>mergedSegmentWarmer
When using Solr for Near Real Time Use Cases, a merged segment warmer can be configured to warm the reader on the newly merged segment, before the merge commits. This is not required for near real-time search, but will reduce search latency on opening a new near real-time reader after a merge completes.
<mergedSegmentWarmer class="org.apache.lucene.index.SimpleMergedSegmentWarmer"/>Compound File Segments
Each Lucene segment is typically comprised of a dozen or so files.
Solr can be configured to bundle all of the files for a Lucene segment into a single compound file using a file extension of .cfs, for "Compound File Segment".
CFS segments may incur a minor performance hit for various reasons, depending on the runtime environment. For example, filesystem buffers are typically associated with open file descriptors, which may limit the total cache space available to each index.
On systems where the number of open files allowed per process is limited, CFS may avoid hitting that limit.
The open files limit might also be tunable for your OS with the Linux/Unix ulimit command, or something similar for other operating systems.
|
CFS: New Segments vs Merged Segments
To configure whether newly written segments should use CFS, see the Many Merge Policy implementations support |
Segments Info Screen
The Segments Info screen in the Admin UI lets you see a visualization of the various segments in the underlying Lucene index for this core, with information about the size of each segment – both bytes and in number of documents – as well as other basic metadata about those segments. Most visible is the number of deleted documents, but you can hover your mouse over the segments to see additional numeric details.
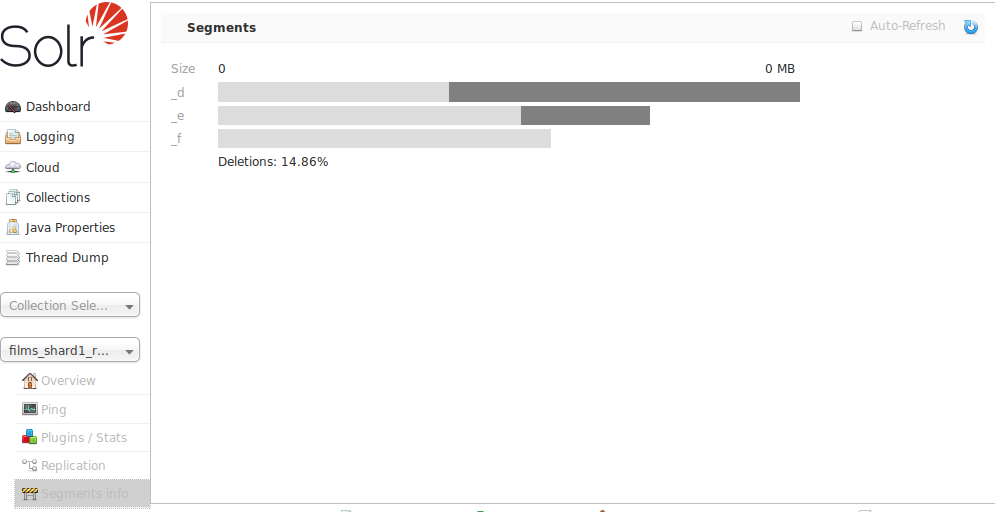
This information may be useful for people to help make decisions about the optimal merge settings for their data.
Index Locks
lockType
The LockFactory options specify the locking implementation to use.
The set of valid lock type options depends on the DirectoryFactory you have configured.
The values listed below are are supported by StandardDirectoryFactory (the default):
-
native(default) usesNativeFSLockFactoryto specify native OS file locking. If a second Solr process attempts to access the directory, it will fail. Do not use when multiple Solr web applications are attempting to share a single index. See also the NativeFSLockFactory javadocs. -
simpleusesSimpleFSLockFactoryto specify a plain file for locking. See also the SimpleFSLockFactory javadocs. -
single(expert) usesSingleInstanceLockFactory. Use for special situations of a read-only index directory, or when there is no possibility of more than one process trying to modify the index (even sequentially). This type will protect against multiple cores within the same JVM attempting to access the same index.If multiple Solr instances in different JVMs modify an index, this type will not protect against index corruption. See also the SingleInstanceLockFactory javadocs.
-
hdfsusesHdfsLockFactoryto support reading and writing index and transaction log files to a HDFS filesystem. See the section Solr on HDFS for more details on using this feature.
<lockType>native</lockType>Other Indexing Settings
There are a few other parameters that may be important to configure for your implementation. These settings affect how or when updates are made to an index.
deletionPolicy
Controls how commits are retained in case of rollback.
The default is SolrDeletionPolicy, which take ths following parameters:
maxCommitsToKeep-
Optional
Default: none
The maximum number of commits to keep.
maxOptimizedCommitsToKeep-
Optional
Default: none
The maximum number of optimized commits to keep.
maxCommitAge-
Optional
Default: none
The maximum age of any commit to keep. This supports
DateMathParsersyntax.
<deletionPolicy class="solr.SolrDeletionPolicy">
<str name="maxCommitsToKeep">1</str>
<str name="maxOptimizedCommitsToKeep">0</str>
<str name="maxCommitAge">1DAY</str>
</deletionPolicy>infoStream
The InfoStream setting instructs the underlying Lucene classes to write detailed debug information from the indexing process as Solr log messages.
Note that enabling this may substantially increase the size of your logs and can cause some performance lags in high traffic systems.
The default is false.
<infoStream>false</infoStream>