Other Query Parsers
In addition to the main query parsers, there are several other query parsers that can be used instead of or in conjunction with the main parsers for specific purposes.
This section details the other parsers, and gives examples for how they might be used.
Many of these parsers are expressed the same way as Local Params.
Block Join Query Parsers
The Block Join query parsers are used with nested documents to query for parents and/or children.
These parsers are covered in detail in the section Block Join Query Parser.
Boolean Query Parser
The BoolQParser creates a Lucene BooleanQuery which is a boolean combination of other queries.
Sub-queries along with their typed occurrences indicate how documents will be matched and scored.
Parameters
must-
Optional
Default: none
A list of queries that must appear in matching documents and contribute to the score.
must_not-
Optional
Default: none
A list of queries that must not appear in matching documents.
should-
Optional
Default: none
A list of queries should appear in matching documents. For a BooleanQuery with no
mustqueries, one or moreshouldqueries must match a document for the BooleanQuery to match. filter-
Optional
Default: none
A list of queries that must appear in matching documents. However, unlike
must, the score of filter queries is ignored. Also, these queries are cached in filter cache. To avoid caching add eithercache=falseas local parameter, or"cache":"false"property to the underlying Query DSL Object. mm-
Optional
Default:
0The number of optional clauses that must match. By default, no optional clauses are necessary for a match (unless there are no required clauses). If this parameter is set, then the specified number of
shouldclauses is required. If this parameter is not set, the usual rules about boolean queries still apply at search time - that is, a boolean query containing no required clauses must still match at least one optional clause. excludeTags-
Optional
Default: none
Comma separated list of tags for excluding queries from parameters above. See explanation below.
Examples
{!bool must=foo must=bar}{!bool filter=foo should=bar}{!bool should=foo should=bar should=qux mm=2}Parameters might also be multivalue references. The former example above is equivalent to:
q={!bool must=$ref}&ref=foo&ref=barReferred queries might be excluded via tags. Overall the idea is similar to excluding fq in facets.
q={!bool must=$ref excludeTags=t2}&ref={!tag=t1}foo&ref={!tag=t2}barSince the later query is excluded via t2, the resulting query is equivalent to:
q={!bool must=foo}Boost Query Parser
BoostQParser extends the QParserPlugin and creates a boosted query from the input value.
The main value is any query to be "wrapped" and "boosted" — only documents which match that query will match the final query produced by this parser.
Parameter b is a function to be evaluated against each document that matches the original query, and the result of the function will be multiplied into the final score for that document.
Boost Query Parser Examples
Creates a query name:foo which is boosted (scores are multiplied) by the function query log(popularity):
q={!boost b=log(popularity)}name:fooCreates a query name:foo which has its scores multiplied by the inverse of the numeric price field — effectively "demoting" documents which have a high price by lowering their final score:
// NOTE: we "add 1" to the denominator to prevent divide by zero
q={!boost b=div(1,add(1,price))}name:fooThe query(…) function is particularly useful for situations where you want to multiply (or divide) the score for each document matching your main query by the score that document would have from another query.
This example uses local param variables to create a query for name:foo which is boosted by the scores from the independently specified query category:electronics:
q={!boost b=query($my_boost)}name:foo
my_boost=category:electronicsCollapsing Query Parser
The CollapsingQParser is really a post filter that provides more performant field collapsing than Solr’s standard approach when the number of distinct groups in the result set is high.
This parser collapses the result set to a single document per group before it forwards the result set to the rest of the search components. So all downstream components (faceting, highlighting, etc.) will work with the collapsed result set.
Details about using the CollapsingQParser can be found in the section Collapse and Expand Results.
Complex Phrase Query Parser
The ComplexPhraseQParser provides support for wildcards, ORs, etc., inside phrase queries using Lucene’s ComplexPhraseQueryParser.
Under the covers, this query parser makes use of the Span group of queries, e.g., spanNear, spanOr, etc., and is subject to the same limitations as that family or parsers.
Parameters
inOrder-
Optional
Default:
trueSet to
trueto force phrase queries to match terms in the order specified. df-
Optional
Default: none
The default search field.
Examples
{!complexphrase inOrder=true}name:"Jo* Smith"{!complexphrase inOrder=false}name:"(john jon jonathan~) peters*"A mix of ordered and unordered complex phrase queries:
+_query_:"{!complexphrase inOrder=true}manu:\"a* c*\"" +_query_:"{!complexphrase inOrder=false df=name}\"bla* pla*\""Complex Phrase Parser Limitations
Performance is sensitive to the number of unique terms that are associated with a pattern. For instance, searching for "a*" will form a large OR clause (technically a SpanOr with many terms) for all of the terms in your index for the indicated field that start with the single letter 'a'. It may be prudent to restrict wildcards to at least two or preferably three letters as a prefix. Allowing very short prefixes may result in to many low-quality documents being returned.
Notice that it also supports leading wildcards "*a" as well with consequent performance implications. Applying ReversedWildcardFilterFactory in index-time analysis is usually a good idea.
MaxBooleanClauses with Complex Phrase Parser
You may need to increase MaxBooleanClauses in solrconfig.xml as a result of the term expansion above:
<maxBooleanClauses>4096</maxBooleanClauses>This property is described in more detail in the section Query Sizing and Warming.
Stopwords with Complex Phrase Parser
It is not recommended to use stopword elimination with this query parser.
Assume we add the terms the, up, and to to stopwords.txt for a collection, and index a document containing the text "Stores up to 15,000 songs, 25,00 photos, or 150 yours of video" in a field named "features".
While the query below does not use this parser:
q=features:"Stores up to 15,000"the document is returned. The next query that does use the Complex Phrase Query Parser, as in this query:
q=features:"sto* up to 15*"&defType=complexphrasedoes not return that document because SpanNearQuery has no good way to handle stopwords in a way analogous to PhraseQuery. If you must remove stopwords for your use case, use a custom filter factory or perhaps a customized synonyms filter that reduces given stopwords to some impossible token.
Field Query Parser
The FieldQParser extends the QParserPlugin and creates a field query from the input value, applying text analysis and constructing a phrase query if appropriate.
The parameter f is the field to be queried.
Example:
{!field f=myfield}Foo BarThis example creates a phrase query with "foo" followed by "bar" (assuming the analyzer for myfield is a text field with an analyzer that splits on whitespace and lowercase terms).
This is generally equivalent to the Lucene query parser expression myfield:"Foo Bar".
Filters Query Parser
The syntax is:
q={!filters param=$fqs excludeTags=sample}field:text&
fqs=COLOR:Red&
fqs=SIZE:XL&
fqs={!tag=sample}BRAND:Foo
which is equivalent to:
q=+field:text +COLOR:Red +SIZE:XL
The param local parameter uses “$” syntax to refer to a few queries, where excludeTags may omit some of them.
Function Query Parser
The FunctionQParser extends the QParserPlugin and creates a function query from the input value.
This is only one way to use function queries in Solr; for another, more integrated, approach, see the section on Function Queries.
Example:
{!func}log(foo)Function Range Query Parser
The FunctionRangeQParser extends the QParserPlugin and creates a range query over a function.
This is also referred to as frange, as seen in the examples below.
Parameters
l-
Optional
Default: none
The lower bound.
u-
Optional
Default: none
The upper bound.
incl-
Optional
Default:
trueInclude the lower bound.
incu-
Optional
Default:
trueInclude the upper bound.
Examples
{!frange l=1000 u=50000}myfield fq={!frange l=0 u=2.2} sum(user_ranking,editor_ranking)Both of these examples restrict the results by a range of values found in a declared field or a function query. In the second example, we’re doing a sum calculation, and then defining only values between 0 and 2.2 should be returned to the user.
For more information about range queries over functions, see Yonik Seeley’s introductory blog post Ranges over Functions in Solr 1.4.
Graph Query Parser
The graph query parser does a breadth first, cyclic aware, graph traversal of all documents that are "reachable" from a starting set of root documents identified by a wrapped query.
The graph is built according to linkages between documents based on the terms found in from and to fields that you specify as part of the query.
Supported field types are point fields with docValues enabled, or string fields with indexed=true or docValues=true.
For string fields which are indexed=false and docValues=true, please refer to the javadocs for SortedDocValuesField.newSlowSetQuery() for its performance characteristics so indexed=true will perform better for most use-cases.
|
Graph Query Parameters
to-
Optional
Default:
edge_idsThe field name of matching documents to inspect to identify outgoing edges for graph traversal.
from-
Optional
Default:
node_idThe field name in candidate documents to inspect to identify incoming graph edges.
traversalFilter-
Optional
Default: none
An optional query that can be supplied to limit the scope of documents that are traversed.
maxDepth-
Optional
Default:
-1(unlimited)Integer specifying how deep the breadth first search of the graph should go beginning with the initial query.
returnRoot-
Optional
Default:
trueBoolean to indicate if the documents that matched the original query (to define the starting points for graph) should be included in the final results.
returnOnlyLeaf-
Optional
Default:
falseBoolean that indicates if the results of the query should be filtered so that only documents with no outgoing edges are returned.
useAutn-
Optional
Default:
falseBoolean that indicates if Automatons should be compiled for each iteration of the breadth first search, which may be faster for some graphs.
Graph Query Limitations
The graph parser only works in single-node Solr installations, or with SolrCloud and user-managed clusters that use exactly 1 shard.
Graph Query Examples
To understand how the graph parser works, consider the following Directed Cyclic Graph, containing 8 nodes (A to H) and 9 edges (1 to 9):
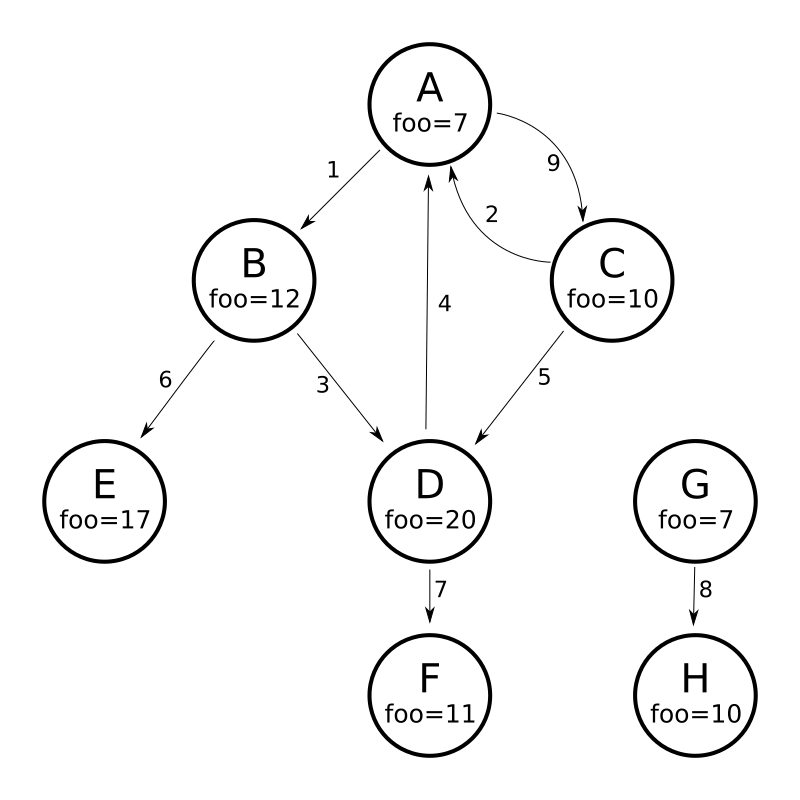
One way to model this graph as Solr documents, would be to create one document per node, with mutivalued fields identifying the incoming and outgoing edges for each node:
curl -H 'Content-Type: application/json' 'http://localhost:8983/solr/my_graph/update?commit=true' --data-binary '[
{"id":"A","foo": 7, "out_edge":["1","9"], "in_edge":["4","2"] },
{"id":"B","foo": 12, "out_edge":["3","6"], "in_edge":["1"] },
{"id":"C","foo": 10, "out_edge":["5","2"], "in_edge":["9"] },
{"id":"D","foo": 20, "out_edge":["4","7"], "in_edge":["3","5"] },
{"id":"E","foo": 17, "out_edge":[], "in_edge":["6"] },
{"id":"F","foo": 11, "out_edge":[], "in_edge":["7"] },
{"id":"G","foo": 7, "out_edge":["8"], "in_edge":[] },
{"id":"H","foo": 10, "out_edge":[], "in_edge":["8"] }
]'With the model shown above, the following query demonstrates a simple traversal of all nodes reachable from node A:
http://localhost:8983/solr/my_graph/query?fl=id&q={!graph+from=in_edge+to=out_edge}id:A"response":{"numFound":6,"start":0,"docs":[
{ "id":"A" },
{ "id":"B" },
{ "id":"C" },
{ "id":"D" },
{ "id":"E" },
{ "id":"F" } ]
}We can also use the traversalFilter to limit the graph traversal to only nodes with maximum value of 15 in the foo field.
In this case that means D, E, and F are excluded – F has a value of foo=11, but it is unreachable because the traversal skipped D:
http://localhost:8983/solr/my_graph/query?fl=id&q={!graph+from=in_edge+to=out_edge+traversalFilter='foo:[*+TO+15]'}id:A...
"response":{"numFound":3,"start":0,"docs":[
{ "id":"A" },
{ "id":"B" },
{ "id":"C" } ]
}The examples shown so far have all used a query for a single document ("id:A") as the root node for the graph traversal, but any query can be used to identify multiple documents to use as root nodes.
The next example demonstrates using the maxDepth parameter to find all nodes that are at most one edge away from a root node with a value in the foo field less than or equal to 10:
http://localhost:8983/solr/my_graph/query?fl=id&q={!graph+from=in_edge+to=out_edge+maxDepth=1}foo:[*+TO+10]...
"response":{"numFound":6,"start":0,"docs":[
{ "id":"A" },
{ "id":"B" },
{ "id":"C" },
{ "id":"D" },
{ "id":"G" },
{ "id":"H" } ]
}Simplified Models
The Document & Field modeling used in the above examples enumerated all of the outgoing and income edges for each node explicitly, to help demonstrate exactly how the "from" and "to" parameters work, and to give you an idea of what is possible. With multiple sets of fields like these for identifying incoming and outgoing edges, it’s possible to model many independent Directed Graphs that contain some or all of the documents in your collection.
But in many cases it can also be possible to drastically simplify the model used.
For example, the same graph shown in the diagram above can be modeled by Solr Documents that represent each node and know only the ids of the nodes they link to, without knowing anything about the incoming links:
curl -H 'Content-Type: application/json' 'http://localhost:8983/solr/alt_graph/update?commit=true' --data-binary '[
{"id":"A","foo": 7, "out_edge":["B","C"] },
{"id":"B","foo": 12, "out_edge":["E","D"] },
{"id":"C","foo": 10, "out_edge":["A","D"] },
{"id":"D","foo": 20, "out_edge":["A","F"] },
{"id":"E","foo": 17, "out_edge":[] },
{"id":"F","foo": 11, "out_edge":[] },
{"id":"G","foo": 7, "out_edge":["H"] },
{"id":"H","foo": 10, "out_edge":[] }
]'With this alternative document model, all of the same queries demonstrated above can still be executed, simply by changing the “from” parameter to replace the “in_edge” field with the “id” field:
http://localhost:8983/solr/alt_graph/query?fl=id&q={!graph+from=id+to=out_edge+maxDepth=1}foo:[*+TO+10]...
"response":{"numFound":6,"start":0,"docs":[
{ "id":"A" },
{ "id":"B" },
{ "id":"C" },
{ "id":"D" },
{ "id":"G" },
{ "id":"H" } ]
}Hash Range Query Parser
The hash range query parser will return documents with a field that contains a value that would be hashed to a particular range.
This is used by the join query parser when using method=crossCollection.
The hash range query parser has a per-segment cache for each field that this query parser will operate on.
When specifying a min/max hash range and a field name with the hash range query parser, only documents that contain a field value that hashes into that range will be returned. If you want to query for a very large result set, you can query for various hash ranges to return a fraction of the documents with each range request.
In the cross collection join case, the hash range query parser is used to ensure that each shard only gets the set of join keys that would end up on that shard.
This query parser uses the MurmurHash3_x86_32. This is the same as the default hashing for the default composite ID router in Solr.
Hash Range Parameters
f-
Optional
Default: none
The field name to operate on. This field should have docValues enabled and should be single-valued.
l-
Optional
Default: none
The lower bound of the hash range for the query.
u-
Optional
Default: none
The upper bound for the hash range for the query.
Hash Range Cache Configuration
The hash range query parser uses a special cache to improve the speedup of the queries.
The following should be added to the solrconfig.xml for the various fields that you want to perform the hash range query on.
Note the name of the cache should be the field name prefixed by “hash_”.
<cache name="hash_field_name"
class="solr.LRUCache"
size="128"
initialSize="0"
regenerator="solr.NoOpRegenerator"/>Join Query Parser
The Join Query Parser allows users to run queries that normalize relationships between documents, similar to SQL-style joins.
Details of this query parser are in the section Join Query Parser.
Learning To Rank Query Parser
The LTRQParserPlugin is a special purpose parser for reranking the top results of a simple query using a more complex ranking query which is based on a machine learnt model.
Example:
{!ltr model=myModel reRankDocs=100}Details about using the LTRQParserPlugin can be found in the Learning To Rank section.
Max Score Query Parser
The MaxScoreQParser extends the LuceneQParser but returns the Max score from the clauses.
It does this by wrapping all SHOULD clauses in a DisjunctionMaxQuery with tie=1.0.
Any MUST or PROHIBITED clauses are passed through as-is.
Non-boolean queries, e.g., NumericRange falls-through to the LuceneQParser parser behavior.
Example:
{!maxscore tie=0.01}C OR (D AND E)MinHash Query Parser
The MinHashQParser builds queries for fields analysed with the MinHashFilterFactory.
The queries measure Jaccard similarity between the query string and MinHash fields; allowing for faster, approximate matching if required.
The parser supports two modes of operation.
The first, when tokens are generated from text by normal analysis; and the second, when explicit tokens are provided.
Currently, the score returned by the query reflects the number of top level elements that match and is not normalised between 0 and 1.
sim-
Required
Default: none
The minimum similarity. The default behaviour is to find any similarity greater than zero. A numeric value between
0.0and1.0. tp-
Optional
Default:
1.0The required true positive rate. For values lower than
1.0, an optimised and faster banded query may be used. The banding behaviour depends on the values ofsimandtprequested. field-
Optional
Default: none
The field in which the MinHash value is indexed. This field is normally used to analyse the text provided to the query parser. It is also used for the query field.
sep-
Optional
Default: " " (empty string)
A separator string. If a non-empty separator string is provided, the query string is interpreted as a list of pre-analysed values separated by the separator string. In this case, no other analysis of the string is performed: the tokens are used as found.
analyzer_field-
Optional
Default: none
This parameter can be used to define how text is analysed, distinct from the query field. It is used to analyse query text when using a pre-analysed string
fieldto store MinHash values. See the example below.
This query parser is registered with the name min_hash.
Example with Analysed Fields
Typical analysis:
<fieldType name="text_min_hash" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.ICUTokenizerFactory"/>
<filter class="solr.ICUFoldingFilterFactory"/>
<filter class="solr.ShingleFilterFactory" minShingleSize="5" outputUnigrams="false" outputUnigramsIfNoShingles="false" maxShingleSize="5" tokenSeparator=" "/>
<filter class="org.apache.lucene.analysis.minhash.MinHashFilterFactory" bucketCount="512" hashSetSize="1" hashCount="1"/>
</analyzer>
</fieldType>
...
<field name="min_hash_analysed" type="text_min_hash" multiValued="false" indexed="true" stored="false" />Here, the input text is split on whitespace, the tokens normalised, the resulting token stream assembled into a stream of all the 5 word shingles which are then hashed. The lowest hashes from each of 512 buckets are kept and produced as the output tokens.
Queries to this field would need to generate at least one shingle so would require 5 distinct tokens.
Example queries:
{!min_hash field="min_hash_analysed"}At least five or more tokens
{!min_hash field="min_hash_analysed" sim="0.5"}At least five or more tokens
{!min_hash field="min_hash_analysed" sim="0.5" tp="0.5"}At least five or more tokensExample with Pre-Analysed Fields
Here, the MinHash is pre-computed, most likely using Lucene analysis inline as shown below. It would be more prudent to get the analyser from the schema.
ICUTokenizerFactory factory = new ICUTokenizerFactory(Collections.EMPTY_MAP);
factory.inform(null);
Tokenizer tokenizer = factory.create();
tokenizer.setReader(new StringReader(text));
ICUFoldingFilterFactory filter = new ICUFoldingFilterFactory(Collections.EMPTY_MAP);
TokenStream ts = filter.create(tokenizer);
HashMap<String, String> args = new HashMap<>();
args.put("minShingleSize", "5");
args.put("outputUnigrams", "false");
args.put("outputUnigramsIfNoShingles", "false");
args.put("maxShingleSize", "5");
args.put("tokenSeparator", " ");
ShingleFilterFactory sff = new ShingleFilterFactory(args);
ts = sff.create(ts);
HashMap<String, String> args2 = new HashMap<>();
args2.put("bucketCount", "512");
args2.put("hashSetSize", "1");
args2.put("hashCount", "1");
MinHashFilterFactory mhff = new MinHashFilterFactory(args2);
ts = mhff.create(ts);
CharTermAttribute termAttribute = ts.getAttribute(CharTermAttribute.class);
ts.reset();
while (ts.incrementToken())
{
char[] buff = termAttribute.buffer();
...
}
ts.end();The schema will just define a multi-valued string value and an optional field to use at anlysis time - similar to above.
<field name="min_hash_string" type="strings" multiValued="true" indexed="true" stored="true"/>
<!-- Optional -->
<field name="min_hash_analysed" type="text_min_hash" multiValued="false" indexed="true" stored="false"/>
<fieldType name="strings" class="solr.StrField" sortMissingLast="true" multiValued="true"/>
<!-- Optional -->
<fieldType name="text_min_hash" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.ICUTokenizerFactory"/>
<filter class="solr.ICUFoldingFilterFactory"/>
<filter class="solr.ShingleFilterFactory" minShingleSize="5" outputUnigrams="false" outputUnigramsIfNoShingles="false" maxShingleSize="5" tokenSeparator=" "/>
<filter class="org.apache.lucene.analysis.minhash.MinHashFilterFactory" bucketCount="512" hashSetSize="1" hashCount="1"/>
</analyzer>
</fieldType>Example queries:
{!min_hash field="min_hash_string" sep=","}HASH1,HASH2,HASH3
{!min_hash field="min_hash_string" sim="0.9" analyzer_field="min_hash_analysed"}Lets hope the config and code for analysis are in syncIt is also possible to query analysed fields using known hashes (the reverse of the above)
{!min_hash field="min_hash_analysed" analyzer_field="min_hash_string" sep=","}HASH1,HASH2,HASH3Pre-analysed fields mean hash values can be recovered per document rather than re-hashed.
An initial query stage that returns the minhash stored field could be followed by a min_hash query to find similar documents.
Banded Queries
The default behaviour of the query parser, given the configuration above is to generate a boolean query and OR 512 constant score term queries together: one for each hash. In this case, generating a score of 1 if one hash matches and a score of 512 if they all match.
A banded query mixes conjunctions and disjunctions. We could have 256 bands each of two queries ANDed together, 128 with 4 hashes ANDed together etc. With fewer bands query performance increases but we may miss some matches. There is a trade-off between speed and accuracy. With 64 bands the score will range from 0 to 64 (the number of bands ORed together)
Given the required similarity and an acceptable true positive rate, the query parser computes the appropriate band size[1]. It finds the minimum number of bands subject to
If there are not enough hashes to fill the final band of the query it wraps to the start.
A Note on Similarity
Low similarities can be meaningful. The number of 5 word hashes is large. Even a single match may indicate some kind of similarity either in meaning, style or structure.
Further Reading
For a general introduction see "Mining of Massive Datasets"[1].
For documents of ~1500 words expect an index size overhead of ~10%; your mileage will vary. 512 hashes would be expected to represent ~2500 words well.
Using a set of MinHash values was proposed in the initial paper[2] but provides a biased estimate of Jaccard similarity. There may be cases where that bias is a good thing. Likewise with rotation and short documents. The implementation is derived from an unbiased method proposed in later work[3].
[1] Leskovec, Jure; Rajaraman, Anand & Ullman, Jeffrey D. "Mining of Massive Datasets", Cambridge University Press; 2 edition (December 29, 2014), Chapter 3, ISBN: 9781107077232.
[2] Broder, Andrei Z. (1997), "On the resemblance and containment of documents", Compression and Complexity of Sequences: Proceedings, Positano, Amalfitan Coast, Salerno, Italy, June 11-13, 1997 (PDF), IEEE, pp. 21–29, doi:10.1109/SEQUEN.1997.666900.
[3] Shrivastava, Anshumali & Li, Ping (2014), "Improved Densification of One Permutation Hashing", 30th Conference on Uncertainty in Artificial Intelligence (UAI), Quebec City, Quebec, Canada, July 23-27, 2014, AUAI, pp. 225-234, http://www.auai.org/uai2014/proceedings/individuals/225.pdf
More Like This Query Parser
The MLTQParser enables retrieving documents that are similar to a given document.
It uses Lucene’s existing MoreLikeThis logic and also works in SolrCloud mode.
Information about how to use this query parser is with the documentation about MoreLikeThis, in the section MoreLikeThis Query Parser.
Nested Query Parser
The NestedParser extends the QParserPlugin and creates a nested query, with the ability for that query to redefine its type via local params.
This is useful in specifying defaults in configuration and letting clients indirectly reference them.
Example:
{!query defType=func v=$q1}If the q1 parameter is price, then the query would be a function query on the price field.
If the q1 parameter is \{!lucene}inStock:true}} then a term query is created from the Lucene syntax string that matches documents with inStock=true.
These parameters would be defined in solrconfig.xml, in the defaults section:
<lst name="defaults">
<str name="q1">{!lucene}inStock:true</str>
</lst>For more information about the possibilities of nested queries, see Yonik Seeley’s blog post Nested Queries in Solr.
Neural Query Parsers
There is currently one Query Parser in Solr to provide Neural Search: knn.
KNN stands for k-nearest neighbors.
Details are documented further in the section Dense Vector Search.
Payload Query Parsers
These query parsers utilize payloads encoded on terms during indexing.
Payloads can be encoded on terms using either the DelimitedPayloadTokenFilter or the NumericPayloadTokenFilter.
Payload Score Parser
PayloadScoreQParser incorporates each matching term’s numeric (integer or float) payloads into the scores.
The main query is parsed from the field type’s query analysis into a SpanQuery based on the value of the operator parameter below.
This parser accepts the following parameters:
f-
Required
Default: none
The field to use.
func-
Required
Default: none
The payload function. The options are:
min,max,average, orsum. operator-
Optional
Default: none
A search operator. The options are: *
orwill generate either aSpanTermQueryor aSpanOrQuerydepending on the number of tokens emitted. *phrasewill generate eitherSpanTermQueryor an ordered, zero slopSpanNearQuery, depending on how many tokens are emitted. includeSpanScore-
Optional
Default:
falseIf
true, multiples the computed payload factor by the score of the original query. Iffalse, the computed payload factor is the score.
Examples
{!payload_score f=my_field_dpf v=some_term func=max}{!payload_score f=payload_field func=sum operator=or}A B CPayload Check Parser
PayloadCheckQParser only matches when the matching terms also have the specified relationship to the payloads.
The default relationship is equals, however, inequality matching can also be performed.
The main query, for both of these parsers, is parsed straightforwardly from the field type’s query analysis into a SpanQuery.
The generated SpanQuery will be either a SpanTermQuery or an ordered, zero slop SpanNearQuery, depending on how many tokens are emitted.
The net effect is that the main query always operates in a manner similar to a phrase query in the standard Lucene parser (thus ignoring any value for q.op).
When the field analysis is applied to the query, if it alters the number of tokens the final number of tokens must match the number of payloads supplied in the payloads parameter.
If there is a mismatch between the number of query tokens and the number of payload values supplied with this query, the query will not match.
|
This parser accepts the following parameters:
f-
Required
Default: none
The field to use.
payloads-
Required
Default: none
A space-separated list of payloads to be compared with payloads in the matching tokens from the document. Each specified payload will be encoded using the encoder determined from the field type prior to matching. Integer, float, and identity (string) encodings are supported with the same meanings as for
DelimitedPayloadTokenFilter. op-
Optional
Default:
eqThe inequality operation to apply to the payload check. All operations require that consecutive tokens derived from the analysis of the query match consecutive tokens in the document, and additionally the payloads on the document tokens must be: *
eq: equal to the specified payloads *gt: greater than the specified payloads *lt: less than the specified payloads *gte: greater than or equal to the specified payloads *lte: less than or equal to the specified payloads
Examples
Find all documents with the phrase "searching stuff" where searching has a payload of "VERB" and "stuff" has a payload of "NOUN":
{!payload_check f=words_dps payloads="VERB NOUN"}searching stuffFind all documents with "foo" where "foo" has a payload with a value of greater than or equal to 0.75:
{!payload_check f=words_dpf payloads="0.75" op="gte"}fooFind all documents with the phrase "foo bar" where term "foo" has a payload greater than 9 and "bar" has a payload greater than 5:
{!payload_check f=words_dpi payloads="9 5" op="gt"}foo bar
Prefix Query Parser
PrefixQParser extends the QParserPlugin by creating a prefix query from the input value.
Currently, no analysis or value transformation is done to create this prefix query.
The parameter is f, the field.
The string after the prefix declaration is treated as a wildcard query.
Example:
{!prefix f=myfield}fooThis would be generally equivalent to the Lucene query parser expression myfield:foo*.
Raw Query Parser
RawQParser extends the QParserPlugin by creating a term query from the input value without any text analysis or transformation.
This is useful in debugging, or when raw terms are returned from the terms component (this is not the default).
The only parameter is f, which defines the field to search.
Example:
{!raw f=myfield}Foo BarThis example constructs the query: TermQuery(Term("myfield","Foo Bar")).
For easy filter construction to drill down in faceting, the TermQParserPlugin is recommended.
For full analysis on all fields, including text fields, you may want to use the FieldQParserPlugin.
Ranking Query Parser
The RankQParserPlugin is a faster implementation of ranking-related features of FunctionQParser and can work together with specialized field of RankFields type.
It allows queries like:
http://localhost:8983/solr/techproducts?q=memory _query_:{!rank f='pagerank', function='log' scalingFactor='1.2'}Re-Ranking Query Parser
The ReRankQParserPlugin is a special purpose parser for Re-Ranking the top results of a simple query using a more complex ranking query.
Details about using the ReRankQParserPlugin can be found in the Query Re-Ranking section.
Simple Query Parser
The Simple query parser in Solr is based on Lucene’s SimpleQueryParser. This query parser is designed to allow users to enter queries however they want, and it will do its best to interpret the query and return results.
This parser takes the following parameters:
q.operators-
Optional
Default: see description
Comma-separated list of names of parsing operators to enable. By default, all operations are enabled, and this parameter can be used to effectively disable specific operators as needed, by excluding them from the list. Passing an empty string with this parameter disables all operators.
Name Operator Description Example query AND+Specifies AND
token1+token2OR|Specifies OR
token1|token2NOT-Specifies NOT
-token3PREFIX*Specifies a prefix query
term*PHRASE"Creates a phrase
"term1 term2"PRECEDENCE( )Specifies precedence; tokens inside the parenthesis will be analyzed first. Otherwise, normal order is left to right.
token1 + (token2 | token3)ESCAPE\Put it in front of operators to match them literally
C+\+WHITESPACEspace or
[\r\t\n]Delimits tokens on whitespace. If not enabled, whitespace splitting will not be performed prior to analysis – usually most desirable.
Not splitting whitespace is a unique feature of this parser that enables multi-word synonyms to work. However, it probably actually won’t unless synonyms are configured to normalize instead of expand to all that match a given synonym. Such a configuration requires normalizing synonyms at both index time and query time. Solr’s analysis screen can help here.
term1 term2FUZZY~~NAt the end of terms, specifies a fuzzy query.
"N" is optional and may be either "1" or "2" (the default)
term~1NEAR~NAt the end of phrases, specifies a NEAR query
"term1 term2"~5 q.op-
Optional
Default:
ORDefines the default operator to use if none is defined by the user. Allowed values are
ANDandOR.ORis used if none is specified. qf-
Optional
Default: none
A list of query fields and boosts to use when building the query.
df-
Optional
Default: none
Defines the default field if none is defined in the Schema, or overrides the default field if it is already defined.
Any errors in syntax are ignored and the query parser will interpret queries as best it can. However, this can lead to odd results in some cases.
Spatial Query Parsers
There are two spatial QParsers in Solr: geofilt and bbox.
But there are other ways to query spatially: using the frange parser with a distance function, using the standard (lucene) query parser with the range syntax to pick the corners of a rectangle, or with RPT and BBoxField you can use the standard query parser but use a special syntax within quotes that allows you to pick the spatial predicate.
All these options are documented further in the section Spatial Search.
Surround Query Parser
The SurroundQParser enables the Surround query syntax, which provides proximity search functionality.
There are two positional operators: w creates an ordered span query and n creates an unordered one.
Both operators take a numeric value to indicate distance between two terms.
The default is 1, and the maximum is 99.
Note that the query string is not analyzed in any way.
Example:
{!surround} 3w(foo, bar)This example finds documents where the terms "foo" and "bar" are no more than 3 terms away from each other (i.e., no more than 2 terms between them).
This query parser will also accept boolean operators (AND, OR, and NOT, in either upper- or lowercase), wildcards, quoting for phrase searches, and boosting.
The w and n operators can also be expressed in upper- or lowercase.
The non-unary operators (everything but NOT) support both infix (a AND b AND c) and prefix AND(a, b, c) notation.
Switch Query Parser
SwitchQParser is a QParserPlugin that acts like a "switch" or "case" statement.
The primary input string is trimmed and then prefixed with case. for use as a key to look up a "switch case" in the parser’s local params.
If a matching local param is found the resulting parameter value will then be parsed as a subquery, and returned as the parse result.
The case local param can be optionally be specified as a switch case to match missing (or blank) input strings.
The default local param can optionally be specified as a default case to use if the input string does not match any other switch case local params.
If default is not specified, then any input which does not match a switch case local param will result in a syntax error.
In the examples below, the result of each query is "XXX":
{!switch case.foo=XXX case.bar=zzz case.yak=qqq}foo} and bar is trimmed automatically.{!switch case.foo=qqq case.bar=XXX case.yak=zzz} bar{!switch case.foo=qqq case.bar=zzz default=XXX}asdfcase instead.{!switch case=XXX case.bar=zzz case.yak=qqq}A practical usage of this parser, is in specifying appends filter query (fq) parameters in the configuration of a SearchHandler, to provide a fixed set of filter options for clients using custom parameter names.
Using the example configuration below, clients can optionally specify the custom parameters in_stock and shipping to override the default filtering behavior, but are limited to the specific set of legal values (shipping=any|free, in_stock=yes|no|all).
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="in_stock">yes</str>
<str name="shipping">any</str>
</lst>
<lst name="appends">
<str name="fq">{!switch case.all='*:*'
case.yes='inStock:true'
case.no='inStock:false'
v=$in_stock}</str>
<str name="fq">{!switch case.any='*:*'
case.free='shipping_cost:0.0'
v=$shipping}</str>
</lst>
</requestHandler>Term Query Parser
TermQParser extends the QParserPlugin by creating a single term query from the input value equivalent to readableToIndexed().
This is useful for generating filter queries from the external human-readable terms returned by the faceting or terms components.
The only parameter is f, for the field.
Example:
{!term f=weight}1.5For text fields, no analysis is done since raw terms are already returned from the faceting and terms components. To apply analysis to text fields as well, see the Field Query Parser, above.
If no analysis or transformation is desired for any type of field, see the Raw Query Parser, above.
Terms Query Parser
TermsQParser functions similarly to the Term Query Parser but takes in multiple values separated by commas and returns documents matching any of the specified values.
This can be useful for generating filter queries from the external human-readable terms returned by the faceting or terms components, and may be more efficient in some cases than using the Standard Query Parser to generate a boolean query since the default implementation method avoids scoring.
This query parser takes the following parameters:
f-
Required
Default: none
The field on which to search.
separator-
Optional
Default:
,(comma)Separator to use when parsing the input. If set to " " (a single blank space), will trim additional white space from the input terms.
method-
Optional
Default:
termsFilterDetermine which of several query implementations should be used by Solr.
Options are restricted to:
termsFilter,booleanQuery,automaton,docValuesTermsFilterPerSegment,docValuesTermsFilterTopLevelordocValuesTermsFilter.Each implementation has its own performance characteristics, and users are encouraged to experiment to determine which implementation is most performant for their use-case. Heuristics are given below.
booleanQuerycreates aBooleanQueryrepresenting the request. Scales well with index size, but poorly with the number of terms being searched for.termsFilteruses aBooleanQueryor aTermInSetQuerydepending on the number of terms. Scales well with index size, but only moderately with the number of query terms.docValuesTermsFiltercan only be used on fields with docValues data. Thecacheparameter is false by default. Chooses between thedocValuesTermsFilterTopLevelanddocValuesTermsFilterPerSegmentmethods using the number of query terms as a rough heuristic. Users should typically use this method instead of usingdocValuesTermsFilterTopLevelordocValuesTermsFilterPerSegmentdirectly, unless they’ve done performance testing to validate one of the methods on queries of all sizes. Depending on the implementation picked, this method may rely on expensive data structures which are lazily populated after each commit. If you commit frequently and your use-case can tolerate a static warming query, consider adding one tosolrconfig.xmlso that this work is done as a part of the commit itself and not attached directly to user requests.docValuesTermsFilterTopLevelcan only be used on fields with docValues data. Thecacheparameter is false by default. Uses top-level docValues data structures to find results. These data structures are more efficient as the number of query terms grows high (over several hundred). But they are also expensive to build and need to be populated lazily after each commit, causing a sometimes-noticeable slowdown on the first query after each commit. If you commit frequently and your use-case can tolerate a static warming query, consider adding one tosolrconfig.xmlso that this work is done as a part of the commit itself and not attached directly to user requests.docValuesTermsFilterPerSegmentcan only be used on fields with docValues data. Thecacheparameter is false by default. It is more efficient than the "top-level" alternative with small to medium (~500) numbers of query terms, and doesn’t suffer a slowdown on queries immediately following a commit (asdocValuesTermsFilterTopLeveldoes - see above). But it is less performant on very large numbers of query terms.automatoncreates anAutomatonQueryrepresenting the request with each term forming a union. Scales well with index size and moderately with the number of query terms.
Examples
{!terms f=tags}software,apache,solr,lucene{!terms f=categoryId method=booleanQuery separator=" "}8 6 7 5309XML Query Parser
The XmlQParserPlugin extends the QParserPlugin and supports the creation of queries from XML. Example:
| Parameter | Value |
|---|---|
defType |
|
q |
|
The XmlQParser implementation uses the SolrCoreParser class which extends Lucene’s CoreParser class. XML elements are mapped to QueryBuilder classes as follows:
| XML element | QueryBuilder class |
|---|---|
<BooleanQuery> |
|
<BoostingTermQuery> |
|
<ConstantScoreQuery> |
|
<DisjunctionMaxQuery> |
|
<MatchAllDocsQuery> |
|
<RangeQuery> |
|
<SpanFirst> |
|
<SpanPositionRange> |
|
<SpanNear> |
|
<SpanNot> |
|
<SpanOr> |
|
<SpanOrTerms> |
|
<SpanTerm> |
|
<TermQuery> |
|
<TermsQuery> |
|
<UserQuery> |
|
<LegacyNumericRangeQuery> |
LegacyNumericRangeQuery(Builder) is deprecated |
Customizing XML Query Parser
You can configure your own custom query builders for additional XML elements.
The custom builders need to extend the SolrQueryBuilder or the SolrSpanQueryBuilder class.
Example solrconfig.xml snippet:
<queryParser name="xmlparser" class="XmlQParserPlugin">
<str name="MyCustomQuery">com.mycompany.solr.search.MyCustomQueryBuilder</str>
</queryParser>