Solr is a search server built on top of Apache Lucene, an open source, Java-based, information retrieval library. It is designed to drive powerful document retrieval applications - wherever you need to serve data to users based on their queries, Solr can work for you.
Here is a example of how Solr could integrate with an application:
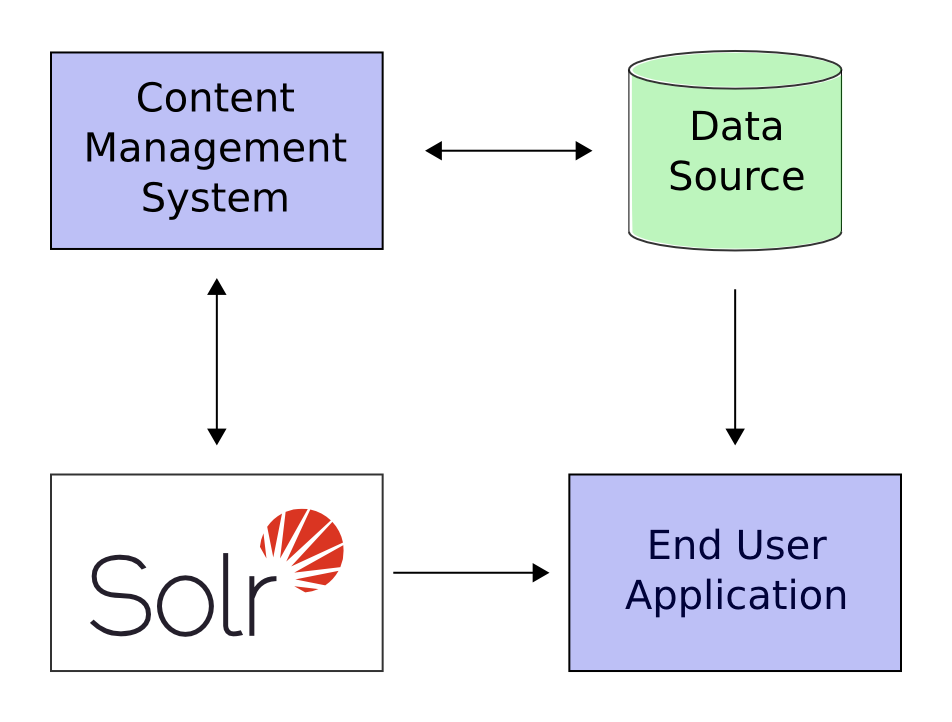
In the scenario above, Solr runs alongside other server applications. For example, an online store application would provide a user interface, a shopping cart, and a way to make purchases for end users; while an inventory management application would allow store employees to edit product information. The product metadata would be kept in some kind of database, as well as in Solr.
Solr makes it easy to add the capability to search through the online store through the following steps:
-
Define a schema. The schema tells Solr about the contents of documents it will be indexing. In the online store example, the schema would define fields for the product name, description, price, manufacturer, and so on. Solr’s schema is powerful and flexible and allows you to tailor Solr’s behavior to your application. See Documents, Fields, and Schema Design for all the details.
-
Feed Solr documents for which your users will search.
-
Expose search functionality in your application.
Because Solr is based on open standards, it is highly extensible. Solr queries are simple HTTP request URLs and the response is a structured document: mainly JSON, but it could also be XML, CSV, or other formats. This means that a wide variety of clients will be able to use Solr, from other web applications to browser clients, rich client applications, and mobile devices. Any platform capable of HTTP can talk to Solr. See Client APIs for details on client APIs.
Solr offers support for the simplest keyword searching through to complex queries on multiple fields and faceted search results. Searching has more information about searching and queries.
If Solr’s capabilities are not impressive enough, its ability to handle very high-volume applications should do the trick.
A relatively common scenario is that you have so much data, or so many queries, that a single Solr server is unable to handle your entire workload. In this case, you can scale up the capabilities of your application using SolrCloud to better distribute the data, and the processing of requests, across many servers. Multiple options can be mixed and matched depending on the scalability you need.
For example: "Sharding" is a scaling technique in which a collection is split into multiple logical pieces called "shards" in order to scale up the number of documents in a collection beyond what could physically fit on a single server. Incoming queries are distributed to every shard in the collection, which respond with merged results. Another technique available is to increase the "Replication Factor" of your collection, which allows you to add servers with additional copies of your collection to handle higher concurrent query load by spreading the requests around to multiple machines. Sharding and replication are not mutually exclusive, and together make Solr an extremely powerful and scalable platform.
Best of all, this talk about high-volume applications is not just hypothetical: some of the famous Internet sites that use Solr today are Macy’s, EBay, and Zappo’s. For more examples, take a look at https://wiki.apache.org/solr/PublicServers.
We welcome feedback on Solr documentation. However, we cannot provide application support via comments. If you need help, please send a message to the Solr User mailing list.