Exercise 1: Index Techproducts Data
This exercise will walk you through how to start Solr as a two-node cluster (both nodes on the same machine) and create a collection during startup. Then you will index some sample data that ships with Solr and do some basic searches.
Launch Solr
To launch Solr, run: bin/solr start -e cloud on Unix or MacOS; bin\solr.cmd start -e cloud on Windows.
This will start an interactive session that will start two Solr "servers" on your machine.
This command has an option to run without prompting you for input (--no-prompt), but we want to modify two of the defaults so we won’t use that option now.
$ bin/solr start -e cloud
Welcome to the SolrCloud example!
This interactive session will help you launch a SolrCloud cluster on your local workstation.
To begin, how many Solr nodes would you like to run in your local cluster? (specify 1-4 nodes) [2]:The first prompt asks how many nodes we want to run.
Note the [2] at the end of the last line; that is the default number of nodes.
Two is what we want for this example, so you can simply press enter.
Ok, let's start up 2 Solr nodes for your example SolrCloud cluster.
Please enter the port for node1 [8983]:This will be the port that the first node runs on. Unless you know you have something else running on port 8983 on your machine, accept this default option also by pressing enter. If something is already using that port, you will be asked to choose another port.
Please enter the port for node2 [7574]:This is the port the second node will run on. Again, unless you know you have something else running on port 7574 on your machine, accept this default option also by pressing enter. If something is already using that port, you will be asked to choose another port.
Solr will now initialize itself and start running on those two nodes. The script will print the commands it uses for your reference.
Starting up 2 Solr nodes for your example SolrCloud cluster.
Creating Solr home directory /solr-{solr-full-version}/example/cloud/node1/solr
Cloning /solr-{solr-full-version}/example/cloud/node1 into
/solr-{solr-full-version}/example/cloud/node2
Starting up Solr on port 8983 using command:
"bin/solr" start -p 8983 --solr-home "example/cloud/node1/solr"
Waiting up to 180 seconds to see Solr running on port 8983 [\]
Started Solr server on port 8983 (pid=34942). Happy searching!
Starting up Solr on port 7574 using command:
"bin/solr" start -p 7574 --solr-home "example/cloud/node2/solr" -z localhost:9983
Waiting up to 180 seconds to see Solr running on port 7574 [\]
Started Solr server on port 7574 (pid=35036). Happy searching!
INFO - 2017-07-27 12:28:02.835; org.apache.solr.client.solrj.impl.ZkClientClusterStateProvider; Cluster at localhost:9983 readyNotice that two instances of Solr have started on two nodes. Because we are starting in SolrCloud mode, and did not define any details about an external ZooKeeper cluster, Solr launches its own ZooKeeper and connects both nodes to it.
After startup is complete, you’ll be prompted to create a collection to use for indexing data.
Now let's create a new collection for indexing documents in your 2-node cluster.
Please provide a name for your new collection: [gettingstarted]Here’s the first place where we’ll deviate from the default options.
This tutorial will ask you to index some sample data included with Solr, called the "techproducts" data.
Let’s name our collection "techproducts" so it’s easy to differentiate from other collections we’ll create later.
Enter techproducts at the prompt and hit enter.
How many shards would you like to split techproducts into? [2]This is asking how many shards you want to split your index into across the two nodes. Choosing "2" (the default) means we will split the index relatively evenly across both nodes, which is a good way to start. Accept the default by hitting enter.
How many replicas per shard would you like to create? [2]A replica is a copy of the index that’s used for failover (see also the Solr Glossary definition). Again, the default of "2" is fine to start with here also, so accept the default by hitting enter.
Please choose a configuration for the techproducts collection, available options are:
_default or sample_techproducts_configs [_default]We’ve reached another point where we will deviate from the default option. Solr has two sample sets of configuration files (called a configset) available out-of-the-box.
A collection must have a configset, which at a minimum includes the two main configuration files for Solr: the schema file (named either managed-schema.xml or schema.xml), and solrconfig.xml.
The question here is which configset you would like to start with.
The _default is a bare-bones option, but note there’s one whose name includes "techproducts", the same as we named our collection.
This configset is specifically designed to support the sample data we want to use, so enter sample_techproducts_configs at the prompt and hit enter.
At this point, Solr will create the collection and again output to the screen the commands it issues.
Created collection 'techproducts' with 2 shard(s), 2 replica(s) with config-set 'techproducts'
SolrCloud example running, please visit: http://localhost:8983/solrCongratulations! Solr is ready for data!
You can see that Solr is running by launching the Solr Admin UI in your web browser: http://localhost:8983/solr/. This is the main starting point for administering Solr.
Solr will now be running two "nodes", one on port 7574 and one on port 8983.
There is one collection created automatically, techproducts, a two shard collection, each with two replicas.
The Cloud tab in the Admin UI diagrams the collection nicely:

Index the Techproducts Data
Your Solr server is up and running, but it doesn’t contain any data yet, so we can’t do any queries.
Solr includes the bin/solr post tool in order to facilitate indexing various types of documents easily.
We’ll use this tool for the indexing examples below.
You’ll need a command shell to run some of the following examples, rooted in the Solr install directory; the shell from where you launched Solr works just fine.
The data we will index is in the example/exampledocs directory.
The documents are in a mix of document formats (JSON, CSV, etc.), and fortunately we can index them all at once:
$ bin/solr post -c techproducts example/exampledocs/*You should see output similar to the following:
Posting files to [base] url http://localhost:8983/solr/techproducts/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file books.csv (text/csv) to [base]
POSTing file books.json (application/json) to [base]/json/docs
POSTing file gb18030-example.xml (application/xml) to [base]
POSTing file hd.xml (application/xml) to [base]
POSTing file ipod_other.xml (application/xml) to [base]
POSTing file ipod_video.xml (application/xml) to [base]
POSTing file manufacturers.xml (application/xml) to [base]
POSTing file mem.xml (application/xml) to [base]
POSTing file money.xml (application/xml) to [base]
POSTing file monitor.xml (application/xml) to [base]
POSTing file monitor2.xml (application/xml) to [base]
POSTing file more_books.jsonl (application/json) to [base]/json/docs
POSTing file mp500.xml (application/xml) to [base]
POSTing file sample.html (text/html) to [base]/extract
POSTing file sd500.xml (application/xml) to [base]
POSTing file solr-word.pdf (application/pdf) to [base]/extract
POSTing file solr.xml (application/xml) to [base]
POSTing file vidcard.xml (application/xml) to [base]
19 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/techproducts/update...
Time spent: 0:00:00.822Congratulations again! You have data in your Solr!
Now we’re ready to start searching.
Basic Searching
Solr can be queried via REST clients, curl, wget, Chrome POSTMAN, etc., as well as via native clients available for many programming languages.
The Solr Admin UI includes a query builder interface via the Query tab for the techproducts collection (at http://localhost:8983/solr/#/techproducts/query).
If you click the Execute Query button without changing anything in the form, you’ll get 10 documents in JSON format:
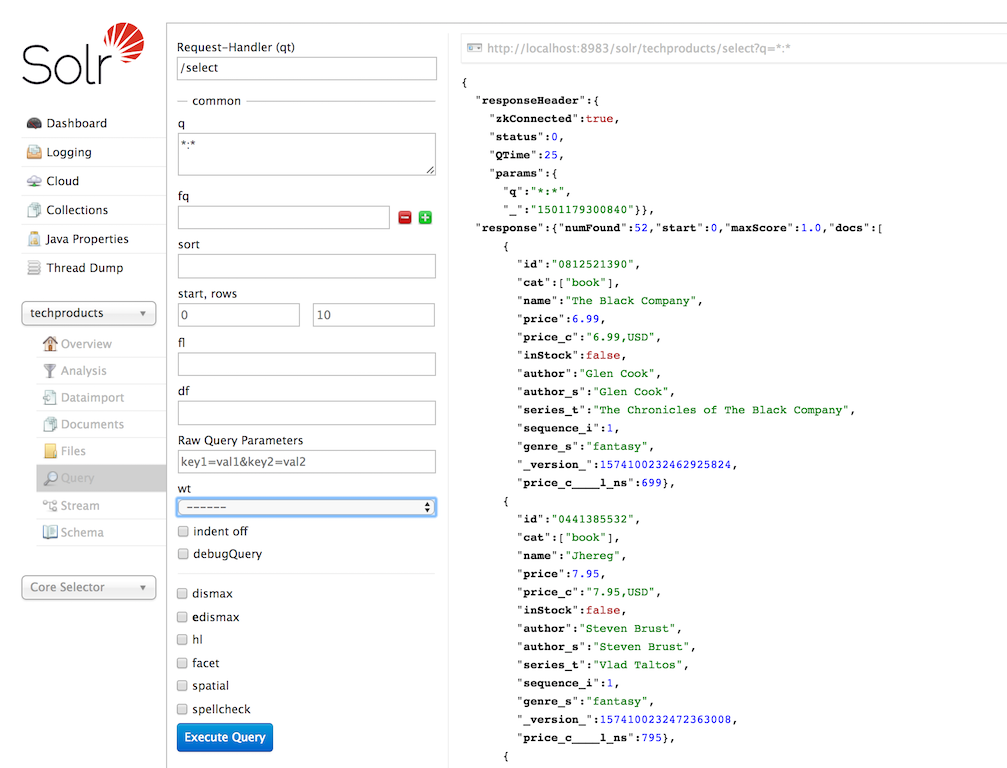
The URL sent by the Admin UI to Solr is shown in light grey near the top right of the above screenshot. If you click on it, your browser will show you the raw response.
To use curl, give the same URL shown in your browser in quotes on the command line:
$ curl "http://localhost:8983/solr/techproducts/select?indent=on&q=*:*"What’s happening here is that we are using Solr’s query parameter (q) with a special syntax that requests all documents in the index (*:*).
All of the documents are not returned to us, however, because of the default for a parameter called rows, which you can see in the form is 10.
You can change the parameter in the UI or in the defaults if you wish.
Solr has very powerful search options, and this tutorial won’t be able to cover all of them. But we can cover some of the most common types of queries.
Search for a Single Term
To search for a term, enter it as the q parameter value in the Solr Admin UI Query screen, replacing *:* with the term you want to find.
Enter "foundation" and hit Execute Query again.
If you prefer curl, enter something like this:
$ curl "http://localhost:8983/solr/techproducts/select?q=foundation"You’ll see something like this:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":8,
"params":{
"q":"foundation"}},
"response":{"numFound":4,"start":0,"maxScore":2.7879646,"docs":[
{
"id":"0553293354",
"cat":["book"],
"name":"Foundation",
"price":7.99,
"price_c":"7.99,USD",
"inStock":true,
"author":"Isaac Asimov",
"author_s":"Isaac Asimov",
"series_t":"Foundation Novels",
"sequence_i":1,
"genre_s":"scifi",
"_version_":1574100232473411586,
"price_c____l_ns":799}]
}}The response indicates that there are 4 hits ("numFound":4).
We’ve only included one document the above sample output, but since 4 hits is lower than the rows parameter default of 10 to be returned, you should see all 4 of them.
Note the responseHeader before the documents.
This header will include the parameters you have set for the search.
By default it shows only the parameters you have set for this query, which in this case is only your query term.
The documents we got back include all the fields for each document that were indexed.
This is, again, default behavior.
If you want to restrict the fields in the response, you can use the fl parameter, which takes a comma-separated list of field names.
This is one of the available fields on the query form in the Admin UI.
Put "id" (without quotes) in the "fl" box and hit Execute Query again. Or, specify it with curl:
$ curl "http://localhost:8983/solr/techproducts/select?q=foundation&fl=id"You should only see the IDs of the matching records returned.
Field Searches
All Solr queries look for documents using some field. Often you want to query across multiple fields at the same time, and this is what we’ve done so far with the "foundation" query. This is possible with the use of copy fields, which are set up already with this set of configurations. We’ll cover copy fields a little bit more in Exercise 2.
Sometimes, though, you want to limit your query to a single field. This can make your queries more efficient and the results more relevant for users.
Much of the data in our small sample data set is related to products.
Let’s say we want to find all the "electronics" products in the index.
In the Query screen, enter "electronics" (without quotes) in the q box and hit Execute Query.
You should get 14 results, such as:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":6,
"params":{
"q":"electronics"}},
"response":{"numFound":14,"start":0,"maxScore":1.5579545,"docs":[
{
"id":"IW-02",
"name":"iPod & iPod Mini USB 2.0 Cable",
"manu":"Belkin",
"manu_id_s":"belkin",
"cat":["electronics",
"connector"],
"features":["car power adapter for iPod, white"],
"weight":2.0,
"price":11.5,
"price_c":"11.50,USD",
"popularity":1,
"inStock":false,
"store":"37.7752,-122.4232",
"manufacturedate_dt":"2006-02-14T23:55:59Z",
"_version_":1574100232554151936,
"price_c____l_ns":1150}]
}}This search finds all documents that contain the term "electronics" anywhere in the indexed fields.
However, we can see from the above there is a cat field (for "category").
If we limit our search for only documents with the category "electronics", the results will be more precise for our users.
Update your query in the q field of the Admin UI so it’s cat:electronics.
Now you get 12 results:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":6,
"params":{
"q":"cat:electronics"}},
"response":{"numFound":12,"start":0,"maxScore":0.9614112,"docs":[
{
"id":"SP2514N",
"name":"Samsung SpinPoint P120 SP2514N - hard drive - 250 GB - ATA-133",
"manu":"Samsung Electronics Co. Ltd.",
"manu_id_s":"samsung",
"cat":["electronics",
"hard drive"],
"features":["7200RPM, 8MB cache, IDE Ultra ATA-133",
"NoiseGuard, SilentSeek technology, Fluid Dynamic Bearing (FDB) motor"],
"price":92.0,
"price_c":"92.0,USD",
"popularity":6,
"inStock":true,
"manufacturedate_dt":"2006-02-13T15:26:37Z",
"store":"35.0752,-97.032",
"_version_":1574100232511160320,
"price_c____l_ns":9200}]
}}Using curl, this query would look like this:
curl "http://localhost:8983/solr/techproducts/select?q=cat:electronics"
Phrase Search
To search for a multi-term phrase, enclose it in double quotes: q="multiple terms here".
For example, search for "CAS latency" by entering that phrase in quotes to the q box in the Admin UI.
If you’re following along with curl, note that the space between terms must be converted to "+" in a URL, as so:
$ curl "http://localhost:8983/solr/techproducts/select?q=\"CAS+latency\""We get 2 results:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":7,
"params":{
"q":"\"CAS latency\""}},
"response":{"numFound":2,"start":0,"maxScore":5.937691,"docs":[
{
"id":"VDBDB1A16",
"name":"A-DATA V-Series 1GB 184-Pin DDR SDRAM Unbuffered DDR 400 (PC 3200) System Memory - OEM",
"manu":"A-DATA Technology Inc.",
"manu_id_s":"corsair",
"cat":["electronics",
"memory"],
"features":["CAS latency 3, 2.7v"],
"popularity":0,
"inStock":true,
"store":"45.18414,-93.88141",
"manufacturedate_dt":"2006-02-13T15:26:37Z",
"payloads":"electronics|0.9 memory|0.1",
"_version_":1574100232590852096},
{
"id":"TWINX2048-3200PRO",
"name":"CORSAIR XMS 2GB (2 x 1GB) 184-Pin DDR SDRAM Unbuffered DDR 400 (PC 3200) Dual Channel Kit System Memory - Retail",
"manu":"Corsair Microsystems Inc.",
"manu_id_s":"corsair",
"cat":["electronics",
"memory"],
"features":["CAS latency 2, 2-3-3-6 timing, 2.75v, unbuffered, heat-spreader"],
"price":185.0,
"price_c":"185.00,USD",
"popularity":5,
"inStock":true,
"store":"37.7752,-122.4232",
"manufacturedate_dt":"2006-02-13T15:26:37Z",
"payloads":"electronics|6.0 memory|3.0",
"_version_":1574100232584560640,
"price_c____l_ns":18500}]
}}Combining Searches
By default, when you search for multiple terms and/or phrases in a single query, Solr will only require that one of them is present in order for a document to match. Documents containing more terms will be sorted higher in the results list.
You can require that a term or phrase is present by prefixing it with a + (plus); conversely, to disallow the presence of a term or phrase, prefix it with a - (minus).
To find documents that contain both terms "electronics" and "music", enter +electronics +music in the q box in the Admin UI Query tab.
If you’re using curl, you must encode the ` character because it has a reserved purpose in URLs (encoding the space character).
The encoding for ` is %2B as in:
$ curl "http://localhost:8983/solr/techproducts/select?q=%2Belectronics%20%2Bmusic"You should only get a single result.
To search for documents that contain the term "electronics" but don’t contain the term "music", enter electronics -music` in the `q` box in the Admin UI.
For curl, again, URL encode ` as %2B as in:
$ curl "http://localhost:8983/solr/techproducts/select?q=%2Belectronics+-music"This time you get 13 results.
More Information on Searching
We have only scratched the surface of the search options available in Solr. For more Solr search options, see Query Syntax and Parsers.
Exercise 1 Wrap Up
At this point, you’ve seen how Solr can index data and have done some basic queries. You can choose now to continue to the next example which will introduce more Solr concepts, such as faceting results and managing your schema, or you can strike out on your own.
If you decide not to continue with this tutorial, the data we’ve indexed so far is likely of little value to you.
You can delete your installation and start over, or you can use the bin/solr script we started out with to delete this collection:
$ bin/solr delete -c techproductsAnd then create a new collection:
$ bin/solr create -c <yourCollection> --shards 2 -rf 2To stop both of the Solr nodes we started, issue the command:
$ bin/solr stop --allFor more information on start/stop and collection options with bin/solr, see Solr Control Script Reference.